機器學習常犯錯的十件事,提到「在分析數據前先繪製圖表的重要性,以及離群值對統計的影響之大」。
筆者在閱讀該文後,發現自己只有透過 console print 出來而已,並沒有進行資料視覺化,可能會產生一些思考盲點。
承襲著我們前一篇要用星期幾分類來個別預測每天的時間的小結,我們試著將每天的關門時間用圖表呈現出來。
在此選用散佈圖作為呈現的方式,讓我們回到 predict.py 實作!
因為目前具體時間這個欄位是字串,一來呈現不易,二來不易進行比較,讓我們先把它轉化為數值。
首先讓我們在讀取 csv 那行以後,建立一個 convert_time_to_int 的 function:
def convert_time_to_int(time_str: str):
time_split_arr = time_str.split(':')
hours_to_minutes = int(time_split_arr[0]) * 60
minutes = int(time_split_arr[1])
total_minutes = hours_to_minutes + minutes
return total_minutes
以上內容為將具體時間裡,冒號以前的小時乘以 60 轉化為分鐘,再加上冒號以後的分鐘加總起來回傳。例如 20:54,加總後即為 1254。
接著讓我們在 df 裡面新增一個欄位,叫 time_in_minutes。我們加在 groupby 那一行後面:
df['time_in_minutes'] = df['具體時間'].apply(convert_time_to_int)
這邊的 apply method 可以將 df 既有的具體時間欄位,透過我們寫好的 convert_time_to_int function 加以處理後,輸入到 time_in_minutes 這一欄。
參考了這篇做法,筆者以星期幾當作 x 軸,剛剛新增的 time_in_minutes 作為 y 軸。
先讓我們 import 套件:
import matplotlib.pyplot as plt
接著實作散佈圖的內容:
# visualization using plt
# ref: https://stackoverflow.com/questions/21654635/scatter-plots-in-pandas-pyplot-how-to-plot-by-category
fig, ax = plt.subplots()
for name, group in group_by_weekdays:
ax.plot(group['星期幾'], group['time_in_minutes'], marker='o', linestyle='', label=name)
ax.legend()
ax.plot 的參數可以代入不同的值,會得到不同的圖表效果,有興趣的讀者不妨試試看。
最後我們需要讓圖表呈現出來:
plt.show()
讓我們執行 predict.py 看圖表: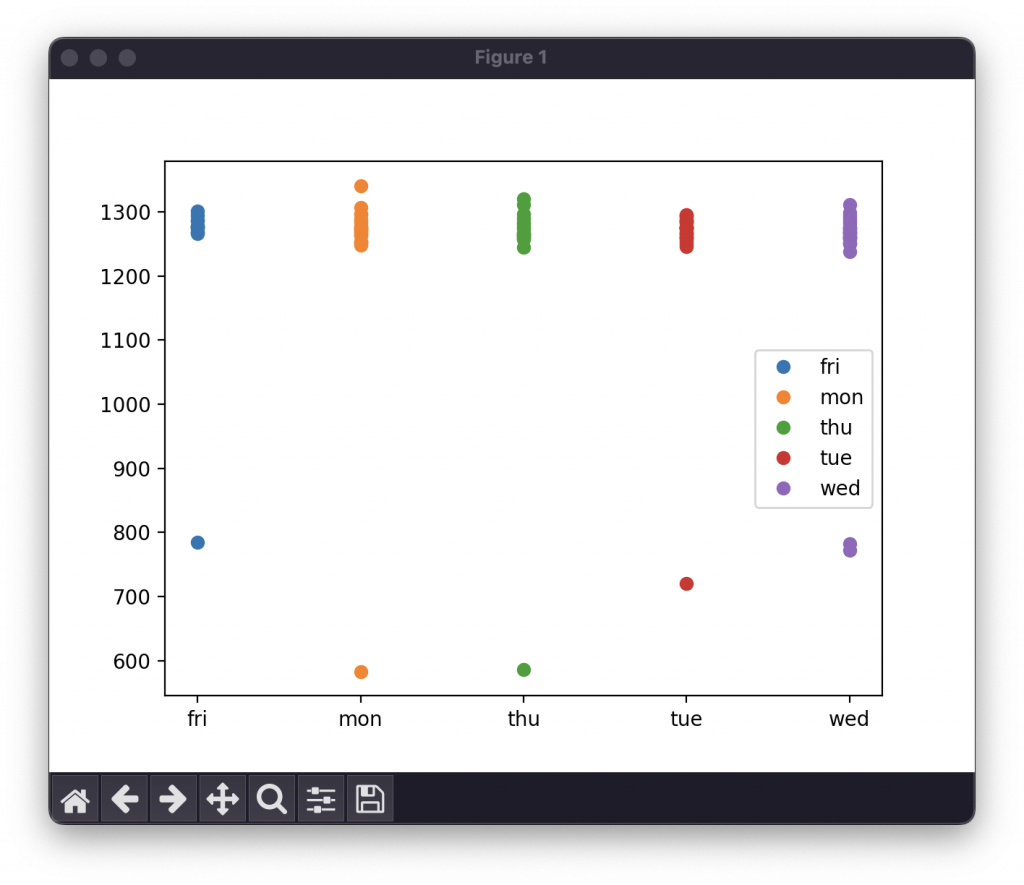
筆者忘記原來自己也有記錄到早上的時間(中午 12:00 為 720,少於 720 者為早上的時間),推測可能是員工上班後的關門聲。
幸好我們有增加視覺化的步驟,才能發現了這些離群值!否則我們如果希望達成的效果是預測晚上人員下班關門的時間,那麼在原始筆數已經夠少的情形,這些早上的時間若連同晚上關門的時間一起處理,就會造成極大的誤差!
預告一下明天我們要決定分析的實作內容。
今天收工!

